Na początek mała uwaga. Nie znam się na statystyce ani nie rozumiem zbytnio narzędzi matematycznych, których się przy tym używa. Zawartość tego posta stanowi tylko i wyłącznie rezultat i sprawozdanie z zabawy (naprawdę!) danymi, którą sobie zafundowałem, więc proszę nie traktować tego jako żadnego rodzaju poradnika, pomocy naukowej do szkoły, ani tym bardziej jako opracowania naukowego!
Jak już wspomniałem, lubię biegać i lubię matematykę. W poprzednim artykule na ten temat zestawiłem wyniki biegaczy z pewnego biegu i otrzymałem ciekawą krzywą. Ale krzywa ta była „mało doskonała”
Zebrałem więc dane z większej ilości biegów. W trakcie tej pracy (trochę to trwało) okazało się jednak, że bieg biegowi nierówny. Różniły się między sobą ilością zawodników jak i różnymi czasami, jakie potrafili osiągać najwolniejsi uczestnicy. Postanowiłem więc jakoś je posegregować.
Problemem jednak okazała się moja nieznajomość narzędzi statystycznych, za których pomocą mógłbym to zrobić. Ale co tam – od czego mam oczy Umieściłem wszystkie biegi na wykresie:
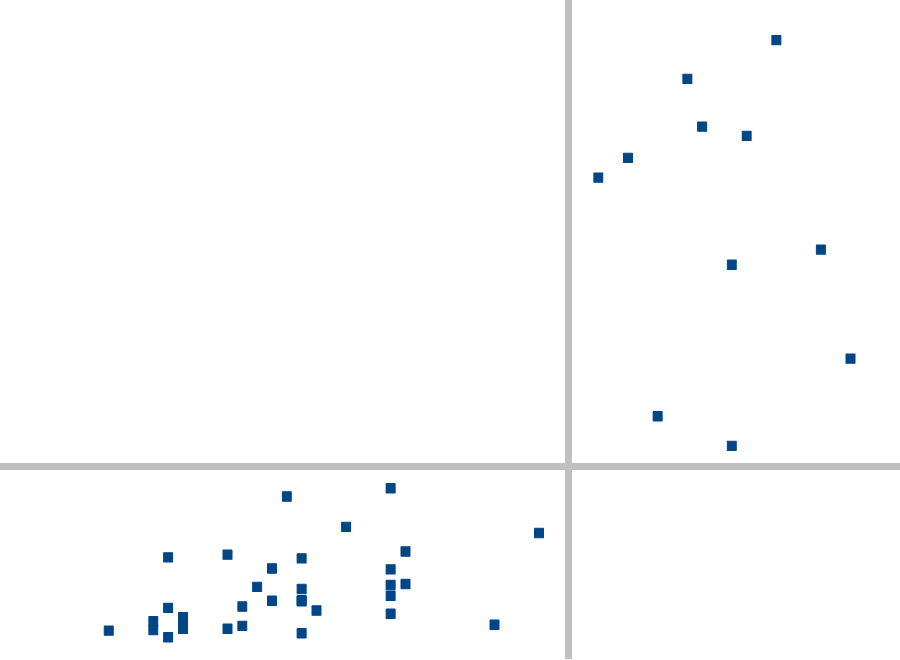
Szare kreski oddzielające umieściłem później. Na osi X są maksymalne czasy, na Y – ilości uczestników. Jak widać, na moje szczęście, wszystkie biegi dzielą się w miarę naturalnie na dwie grupy:
- Te z mniejszą ilością zawodników i bardziej zwartymi czasami (takie trochę bardziej elitarne - lewa, dolna ćwiartka).
- Te z większą ilością zawodników (takie bardziej popularne - prawa, górna ćwiartka).
Można by polemizować, czy ten podział jest rzeczywisty – skrajne przypadki w obu grupach prawie dotykają linii, co oznacza że pod pewnymi względami są dosyć do siebie podobne (ilość zawodników/maksymalne czasy). Jednak dla mojego prostego „eksperymentu” nie ma to istotnego znaczenia.
Co odkryłem?
Po pierwsze – Nie miało właściwie znaczenia, czy uwzględniłem ten rozdział pomiędzy dwoma rodzajami zawodów, czy nie:

Jak widać na powyższym wykresie, zarówno dla biegów elitarnych (żółta linia), tych popularnych (linia czerwona) jak i wszystkich wziętych razem (linia niebieska) rozkład czasów przedstawia się podobnie!
Druga moja obserwacja ma związek z poczynionym wcześniej spostrzeżeniem o „niedoborze” osób o czasach przeciętnych. Okazuje się, że niedobór ten istnieje tylko dla tamtego jednego biegu, który wtedy przeanalizowałem. Tym razem, po uwzględnieniu ponad 40 biegów okazuje się, że istnieje dosyć spory nadmiar osób o czasach trochę lepszych, niż przeciętne – albo to, albo niedobór osób od nich wolniejszych. Mówię tak, ponieważ nie mogłem niestety jednoznacznie stwierdzić, jakiego rodzaju jest to rozkład.
Wizualnie rzeczywiście przypomina rozkład Poissona. Jednak lepsze dopasowanie daje rozkład Gaussa (są to bardzo podobne rozkłady – i podobieństwo to nie ogranicza się jedynie do wyglądu).

Ciemnozielona linia przedstawia rozkład Gaussa, jasnozielona zaś rozkład Poissona. Linia czerwona przedstawia rozkład biegów. Rozkłady te dopasowałem obliczając ich podstawowe parametry na podstawie zebranych danych: średnią i odchylenie standardowe.
Widać, że nie są zbytnio dopasowane. Może gdyby jakoś usunąć ten „róg” przy szczycie wykresu... Ale wtedy należałoby z kolei wyjaśnić jego obecność w pierwotnych danych.
I to właściwie wszystko. Do niczego szczególnego nie doszedłem – miałem tylko trochę zabawy i otrzymałem parę niewyjaśnionych co prawda, ale ciekawych rezultatów.
Brak komentarzy:
Prześlij komentarz